前面兩篇都是用較小的模型做改進,這一篇開始要嘗試著使用較大模型、較大輸入、集成模型
什麼意思呢?以下分別解釋
但要考慮到gpu ram 可能會不夠,所以我們先用較小的數據集來嘗試
所以先看一下哪個標籤的數據較少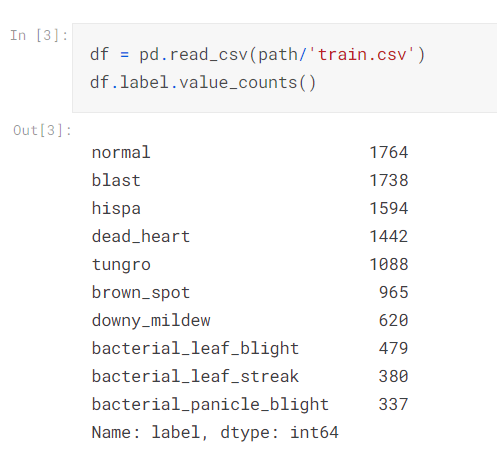
明顯可以看出bacterial_panicle_blight 只有 337筆。
接下來改良一下我們的train
其中多加了一個新的東西,叫做梯度累積(gradient accumulation)。梯度累積是一種技術,可以在每個小批次(batch)處理後不立即更新模型參數,而是將梯度累積起來,直到一定數量的小批次後再進行一次參數更新。這有助於處理具有較大批次大小但內存有限的情況。通過 accum 參數,可以指定要將多少個小批次的梯度進行累積,並且將梯度累積的操作添加到訓練過程中。
def train(arch, size, item=Resize(480, method='squish'), accum=1, finetune=True, epochs=12):
dls = ImageDataLoaders.from_folder(trn_path, valid_pct=0.2, item_tfms=item,
batch_tfms=aug_transforms(size=size, min_scale=0.75), bs=64//accum)
cbs = GradientAccumulation(64) if accum else []
learn = vision_learner(dls, arch, metrics=error_rate, cbs=cbs).to_fp16()
if finetune:
learn.fine_tune(epochs, 0.01)
return learn.tta(dl=dls.test_dl(tst_files))
else:
learn.unfreeze()
learn.fit_one_cycle(epochs, 0.01)
注意在這邊還有一個新的參數叫做finetune,可用於指定是使用 fine_tune() 還是 fit_one_cycle() 來進行模型訓練。如果使用 fine_tune(),則該函數還將計算並返回對測試數據集進行測試時間增強(TTA)預測的結果。
梯度累積是一種深度學習訓練技術,允許我們在處理大批次數據時節省內存。通常在訓練過程中,我們會根據每個小批次計算梯度並更新模型權重。但當內存有限時,這可能會成為一個問題。梯度累積的做法是將多個小批次的梯度相加,然後再執行權重更新。這樣,我們可以實現較大的批次大小,同時減少內存需求。
在以下程式中,我們首先初始化一個計數器(count)來跟蹤已處理的樣本數。然後,遍歷數據加載器,計算每個小批次的梯度。每次處理一個小批次,我們將計數器增加該小批次的樣本數。當計數器超過指定的目標(這裡是 64)時,我們執行權重更新,並將計數器重置為零。這樣,我們可以實現與原始批次大小幾乎相同的訓練效果,但使用的內存量僅為原批次大小的 1/accum。
這種技巧對於在有限內存下訓練大型模型非常有用
for x,y in dl:
calc_loss(coeffs, x, y).backward()
coeffs.data.sub_(coeffs.grad * lr)
coeffs.grad.zero_()
count = 0 # track count of items seen since last weight update
for x,y in dl:
count += len(x) # update count based on this minibatch size
calc_loss(coeffs, x, y).backward()
if count>64: # count is greater than accumulation target, so do weight update
coeffs.data.sub_(coeffs.grad * lr)
coeffs.grad.zero_()
count=0 # reset count
然後我們選用convnext_small_in22k,這是一種卷積神經網絡(CNN)模型,但不是大型模型。它是一種比較輕量級的模型,通常用於計算效率較低的場景或內存有限的情況下。這種模型在性能和模型大小之間取得了平衡,通常不如大型模型(如ResNet-50、EfficientNet 等)在精度上表現出色,但在內存和計算效率方面更有優勢。
選擇模型時,需要根據特定的任務、數據集大小、內存限制和計算資源來平衡性能和效率。convnext_small_in22k 通常用於較小的數據集或需要更快速訓練的情況。如果有足夠的計算資源和大型數據集,則可以考慮使用更大的模型以提高預測性能。
那這邊跟一開始所謂的大模型有什麼關係呢?
大概看了一下,這邊會用數個小模型做集成。
接下來看一下如果內存不夠的話,怎麼辦?
講師有一些小技巧
import gc
def report_gpu():
print(torch.cuda.list_gpu_processes())
gc.collect()
torch.cuda.empty_cache()
report_gpu()
先查看一下當前環境的gpu訊息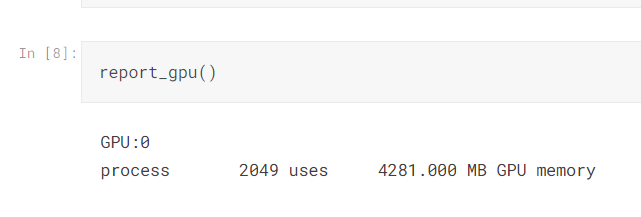
看起來光是accum=1 就消耗了4gb 多的顯存!
然後講師跟著嘗試著用慢慢調整accum的值,觀察顯存的使用情況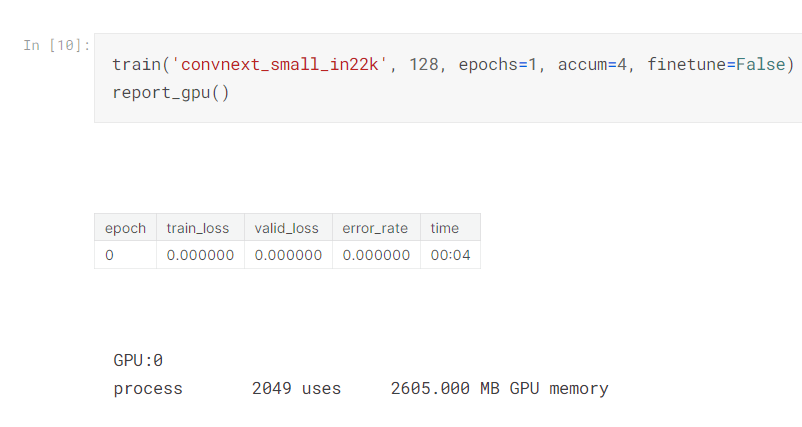
發現這樣可以降低顯存使用率! accm=4 也就是執行4個批次才做一次權重更新不過可能會增加一些訓練時間。
所以我們可以根據自己的gpu 的顯存大小,調整accm的值
講師為了要符合他16gb 顯存的大小,來跑convnext_large_in22k 這個模型,所以調整accum=2
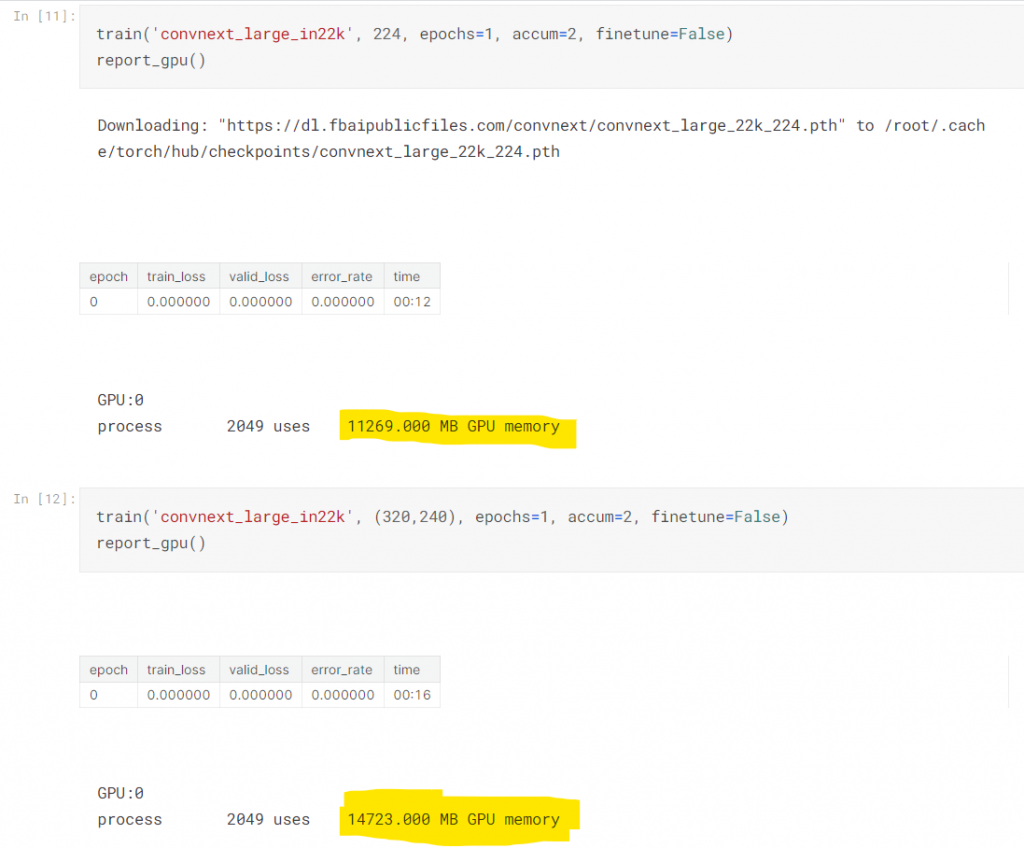
講師接著跑了一些不同的模型,並調整accum值確保他的gpu不會爆掉
接著就創立一個dict ,儲存這些模型的設定,並且準備之後要做Ensembling
res = 640,480
models = {
'convnext_large_in22k': {
(Resize(res), (320,224)),
}, 'vit_large_patch16_224': {
(Resize(480, method='squish'), 224),
(Resize(res), 224),
}, 'swinv2_large_window12_192_22k': {
(Resize(480, method='squish'), 192),
(Resize(res), 192),
}, 'swin_large_patch4_window7_224': {
(Resize(res), 224),
}
}
trn_path = path/'train_images'
tta_res = []
for arch,details in models.items():
for item,size in details:
print('---',arch)
print(size)
print(item.name)
tta_res.append(train(arch, size, item=item, accum=2)) #, epochs=1))
gc.collect()
torch.cuda.empty_cache()
在這個迴圈中,把我們有興趣的模型都跑一遍,接下來要做集成了。
跑完上面的模型,講師發現vit 這個模型的效果比較好,所以他決定把這個模型的權重加重
save_pickle('tta_res.pkl', tta_res)
tta_prs = first(zip(*tta_res))
tta_prs += tta_prs[1:3] # 2倍權重
所以把加權過後的每個結果取平均
avg_pr = torch.stack(tta_prs).mean(0)
avg_pr.shape
這樣就把集成給做完了!
最後執行的程式為
dls = ImageDataLoaders.from_folder(trn_path, valid_pct=0.2, item_tfms=Resize(480, method='squish'),
batch_tfms=aug_transforms(size=224, min_scale=0.75))
idxs = avg_pr.argmax(dim=1)
vocab = np.array(dls.vocab)
ss = pd.read_csv(path/'sample_submission.csv')
ss['label'] = vocab[idxs]
ss.to_csv('subm.csv', index=False)
接下來就submit 吧!


 iThome鐵人賽
iThome鐵人賽